

What’s Your Problem?
Let’s assume you have a problem: limited resources to counter potential terrorist events in a geographic area of interest.
To solve the challenge, you’ve decided to try and use previous attack information to see if you can prevent (or at least predict) future mayhem. Perhaps you also consider looking for other examples of how to tackle this problem. Just maybe, a mixture of nature, technology, and a mound of data can help.
Where to Begin?
To get started, you’ll need to combine two things:
- an immense volume and variety of data available (everything possible in the environment, not just your own data);
- machine learning
From this combination, you can build a machine learning model that can be trained to find patterns. Then, you match these patterns against new data, run it through millions of iterations, and voilà – you can make informed predictions about future events (a.k.a. predictive analytics). To predict the most likely future results you’ll need to filter out unlikely outcomes and process millions of records in a matter of seconds. Sounds easy enough, right? Let’s start with learning how to reduce unlikely paths in analysis, which could block future success.
Swarm and Predictive Intelligence
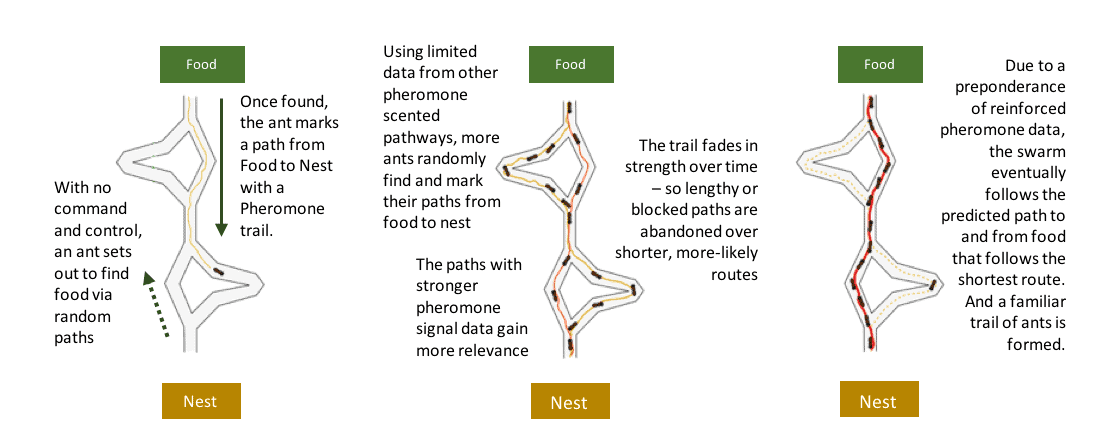
Without going in-depth across various types of predictive analytics capabilities, we’ll focus on a type of controlled chaos used in nature to understand random events: swarm intelligence. In this situation, we combine a decentralized learning engine with a decentralized forecasting model. To simplify swarm intelligence, the infographic below demonstrates how ants use random variations of data to predict preferred outcomes.[1] The incentive for the ants is obvious: a path to food. However, the added benefit of their scenario is the same as yours – ending at a future state — one that best reduces risks based on what happened in the past.
 Predicting Future Events in our World
Predicting Future Events in our World
 Predicting Future Events in our World
Predicting Future Events in our WorldFrom the example above, keep in mind that ants are blind; they have no data scientists studying findings, and there is no defined leader deciding their courses of action. Decisions are directly based on most likely pathways to the best possible answer. In much the same way, you can use collections of data surrounding events to leverage past findings from experiences and apply a process model to connect those findings to their possible origins, then forecast future outcomes through random variations and tests against the model you built. This general reasoning and learning approach is applicable to a wide range of domains and scenarios. We refer to the process as event risk forecasting, or ERF.
For ERF to work, there are three, vitally-important, main ingredients:
- The ability to ingest, exploit, make sense of, and create a knowledge base of information that can be used as the source or training set;
- The power to process these mountains of data, efficiently and fast.
- The ability to create a continuously learning activity model from this data, while continuously leveraging it to predict future events (covered in Part 2 of this series)
Leverage All of Your Data
Ingredient #1: Fused Data
The complexity of predicting terrorist activity, understanding millions of objects in the space domain, or even determining the optimum logistics for troop and equipment sustainment obviously all have more requirements than ants finding a picnic basket in the park. In our human world of problems there are myriad data points – geospatial, patterns of life, measurements, signals, open source info, and more information, which all need to be considered, patterned, and processed.
Intelligent Data Fusion is the process of integrating and correlating all this structured and unstructured data, such as documents, images, full-motion video, social media, news, RSS feeds, event details, facts from text, and geolocation data. This is a necessary first step to properly predicting complex events.
When this fused data is leveraged, it allows you or other analysts to discover relationships between “things” correlated across a knowledge base. You can then conduct link analysis to explore those relationships (i.e. between people, objects, locations, and events).
Analyze your Environment Continuously
Ingredient #2: High Performance Analytics Engine
After you tackle the data fusion process, you’ll need a way to process the mountains of data. If you use older technology, analytical power will be extremely limited by the size, scale, and structure of databases and servers. In modern systems, however, you can reduce the time needed to process and analyze this massive data without being limited by table structure and hardware overhead. SAP NS2 tackles this challenge with in-memory processing and analysis. This capability is provided by our high-performance analytics platform, SAP HANA.
SAP HANA can make millions of calculations required to support analytical analysis in memory without the need to move data from an internal data store to an external analytical engine and back again. SAP HANA can also simultaneously conduct text analysis, graph processing, geospatial processing, and complex, high-speed SQL queries. Processing all of this “in-memory” significantly reduces the network traffic between analytic functions. It also increases security, since sensitive information can remain in a single data platform.
With the foundation on how to lay the foundation for predictive analytics in place, we’ll cover Event Risk Forecasting and a three-phased approach to better outcomes in Part Two.





